| www.mari-language.com: | ENGLISH | МАРЛА | ПО-РУССКИ | |
| Main page » Keyboard Layouts & Fonts » Theory | ||
| www.mari-language.com: | ENGLISH | МАРЛА | ПО-РУССКИ | |
| Main page » Keyboard Layouts & Fonts » Theory | ||
Yes, you should be able to see them right here: ӧ, ӱ, ҥ, ӓ, ӹ. While modern operating systems – Windows, MacOS, and Linux – have their shortcomings when it comes to handling languages like Mari, and while no Mari user interfaces are available (yet), any modern operating system is capable of dealing with the Mari alphabet in its entirety. This section aims to give a detailed overview on the language's "situation" in computing, and on how one can avoid problems when using the special Mari characters.
When talking about a computer's ability to handle certain characters, one must differ between three concepts: character encoding, fonts and keyboard layouts.
Computers store their data in so-called bits. Every bit can be either 1 or 0 – a bit is, thus, the smallest unit of information possible. A character encoding system is needed to translate between this so-called binary data and actual characters. How many characters an encoding system can handle depends on how many bits one uses to represent one character. For example, a system allotting 5 bits to each character could represent 32 (25 = 2 * 2 * 2 * 2 * 2) different characters.
| 00000 = a | 01000 = i | 10000 = q | 11000 = y |
| 00001 = b | 01001 = j | 10001 = r | 11001 = z |
| 00010 = c | 01010 = k | 10010 = s | 11010 = ? |
| 00011 = d | 01011 = l | 10011 = t | 11011 = ? |
| 00100 = e | 01100 = m | 10100 = u | 11100 = ? |
| 00101 = f | 01101 = n | 10101 = v | 11101 = ? |
| 00110 = g | 01110 = o | 10110 = w | 11110 = ? |
| 00111 = h | 01111 = p | 10111 = x | 11111 = ? |
Using this system, the computer would save the word "hello" as "00111|00100|01011|01011|01110".
This would suffice to represent the 26 letters of the standard Latin alphabet, with 6 characters to spare. However, it would not suffice to have upper and lower case versions of all of these letters.
For many years, the so-called ASCII (American Standard Code for Information Interchange) code was dominant in computing, globally. This system used 7 bits per character, making it capable of holding 128 (27 = 2 * 2 * 2 * 2 * 2 * 2 * 2) different characters. This was enough to represent the standard Latin alphabet in both upper and lower case, the numbers 0-9, and various punctuation marks, but there was no room for letters with diacritics or other writing systems. Thus, one had to use a different character encoding if one wished to deal with Russian texts, for example. A multitude of different character encodings for different languages that were not compatible with one another emerged.
In recent years, Unicode has become increasingly dominant. Unicode is one character encoding system intended to cover all languages found on the planet. It allows characters to use up to 32 bits apiece, making this system capable of encoding literally millions of different characters. Unicode can encode letters from virtually any writing system known to man, be it Japanese, Georgian, Egyptian Hieroglyphs, Gothic or Mari. Any modern operating system and modern browser will support Unicode – thus, computers themselves have no problems with Mari.
Problems with character encoding do occur when files are saved in a character encoding other than Unicode. Many programs (for example, Microsoft Word) use Unicode by default. Some programs unfortunately do not allow users to save files in Unicode, making the usage of Mari characters in these problematic. (This is a problem that should fade away in coming years, as Unicode support is increasingly expected from software). Other programs allow users to specify the character encoding when saving files – they do not use Unicode by default, but they can use it.
If you are using the Microsoft Editor in order to create text files or html files for example, you can choose what character encoding you wish to use. Often, different variants of Unicode will be offered. If this is the case, always choose UTF-8 (Unicode Transformation Format).
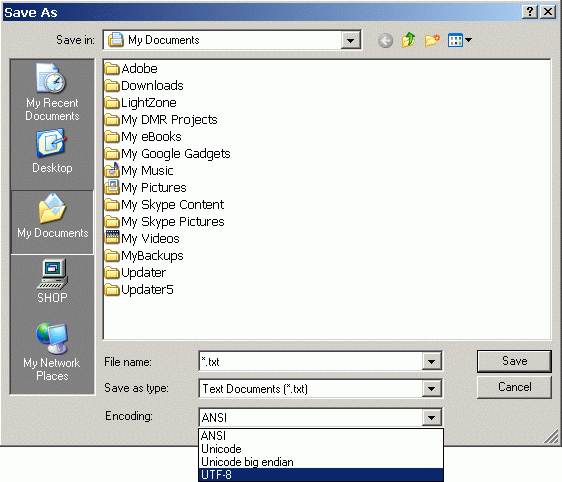
This screenshot was taken in Windows XP. The window's exact layout will differ from operating system to operating system, but the principle should remain the same. If you save a file in UTF-8, you should not have any problems with Mari characters.
Computers use character encoding systems to internally represent data. By default, however, they do not know what an a, b, c or d looks like. In order to display data stored in bits, computers need fonts. Fonts specify the exact appearance of letters.
No font in the world will cover all characters found in Unicode. Some fonts will only cover the standard Latin alphabet (and thus be unsuitable for, e.g., German) some will cover the Latin alphabet with diacritics but not the Cyrillic alphabet (making them suitable for German, but unusable for Russian). Unfortunately, only few cover an expanded Cyrillic alphabet including the special Mari characters, making them problematic for our purpose – even when Unicode is used. Depending on the font and program, different things can happen when a font does not know how to represent a certain character. A white space can be displayed instead of the character, a little box can appear, or the characters can be displayed in a different font, in which said characters exist, resulting in uneven text.
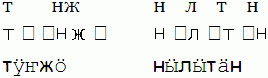
To avoid such difficulties, you must limit yourself to using the small, but growing, number of fonts that support the Mari characters. Some examples:

If you wish to use one of these fonts, but cannot find it on your computer, click here to get instructions on how to obtain and install said font.
One thing one must consider when creating Word documents or web pages is that other people wishing to view them must have the fonts you have used installed as well, for these to be displayed correctly. If you wish to create a document of this sort that you wish to share with others, it is best to use Microsoft Sans Serif, as this font supports the Mari characters and comes pre-installed with all modern operating systems.
Naturally, in many situations, having more fonts at one's disposal would be nice. Using less common fonts, such as the DejaVu fonts, is absolutely no problem if one wishes to publish a "static" document. There are two ways in which you can make sure that your document looks as good for other people as it does for you.
In order to type properly in a language, one must have a keyboard layout that covers all of the characters used by it. It is important to note that this issue is independent from the previously discussed ones – just because users do not have certain characters on their keyboard does not mean that their computers are unable to understand and display them. If one was to work on a German-language word file on an American computer, the German characters ä, ö, ü and ß would be displayed without any problems, one would simply lack the means to produce new characters of this sort directly.
No major operating systems (with the exception of Linux) offer keyboard layouts suited for Mari. Thus, users must install Mari keyboard layouts manually, either as an alternative keyboard layout that they can switch to when necessary, or as a replacement for their standard keyboard layout. We offer installer files for both Windows (XP, Vista, 7) and MacOS X.
Native Maris will generally be using the Russian keyboard layout, which will cover the Mari layout with the exception of a few characters. After following the procedures detailed here (for Windows XP, Windows Vista, Windows 7 and MacOS X), you will be able to access the Mari letters by holding down the right Alt Key – to the right of your space bar – while pressing down the letters а, о, у, н and ы respectively to produce the desired special character.

Note that these modifications will not make it any more difficult to type in Russian using your keyboard. In fact, this update will not be noticeable unless you are typing in Mari.
These keyboard layouts also include a few non-standard Cyrillic letters not used by Mari: ӝ, ӟ, ӥ, ӵ. These are letters used by the Udmurt language. By adding these letters to the layout, it becomes usable for all the larger Finno-Ugric languages spoken in the Russian federation – Mari, Udmurt, Komi and Mordvin.
People not accustomed to the Cyrillic layout can find keyboard layouts tailored to their needs here. These layouts differ from those designed for users of the Russian keyboard layout in that they are as close to the QWERTY layout as possible – Cyrillic characters are placed where their Latin counterparts are, where they exist – the center row of these layouts is асдфгхйклӧ (cf. asdfghjkl(ö)). Cyrillic letters lacking a Latin counterpart are either placed on Latin letters lacking Cyrillic counterparts (я is in the top left corner, where q is on Latin layouts) or at the side of the layout. The layout below, for example, is optimized for users of the German keyboard layouts:

With the Shift key pressed:

With Alt Gr key pressed:

With Alt Gr and Shift key pressed:
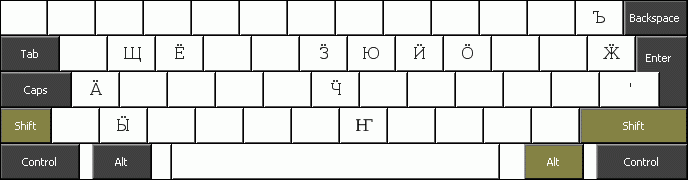
We provide several layouts that differ only slightly from one another. This is due to the fact that while, for example, the German and Finnish keyboard layouts are very similar, punctuation marks are arranged differently on both keyboards.
As of now, we offer the following layouts:
If you desire a different layout (e.g. an Italian-based layout), please contact us, we will create one as soon as possible.
 |
 |
 |
 |
||
| The Mari Web Project is primarily based at the Department of Finno-Ugric Studies at the University of Vienna. The Mari-English Dictionary was funded by the Austrian Science Fund (FWF): P22786-G20. The second stage of the project is being funded by the Kone Foundation: The Mari Web Project: Phase 2. Some of our work is carried out at the Institute of Finno-Ugric and Uralic Studies at the Ludwig Maximilian University of Munich. | ||
| Last update:10 July 2014 | ||