| www.mari-language.com: | ENGLISH | МАРЛА | ПО-РУССКИ | |
| Главная » Шрифты и клавиатуры » Немного теории | ||
| www.mari-language.com: | ENGLISH | МАРЛА | ПО-РУССКИ | |
| Главная » Шрифты и клавиатуры » Немного теории | ||
Да, доказательство – символы, которые вы видите здесь: «ӧ», «ӱ», «ҥ», «ӓ», «ӹ». Несмотря на отсутcтвие интерфейсов на марийском языке и некоторые ограничения, возникающие при работе с марийским алфавитом в Windows, MacOS и Linux, в целом современные операционные системы в состоянии распознавать все марийские символы. В этом разделе описаны общие принципы кодирования языковых символов в компьютерных системах, а также особенности кодирования марийских символов.
Способность компьютера распознавать символы зависит от трех факторов: системы кодирования символов, шрифта и раскладки клавиатуры.
Минимальной единицей количества информации в компьютерных системах является бит. Один бит позволяет хранить одну цифру двоичной системы счисления: «0» или «1». Для преобразования этой двоичной числовой системы в привычные нам текстовые символы необходима система кодирования символов. Количество символов, которые можно закодировать в той или иной системе кодирования, зависит от количества бит, используемых для кодировки одного символа. Так, например, система, в которой каждый символ представлен 5 битами, в состоянии кодировать 32 (25 = 2 * 2 * 2 * 2 * 2) различных символа.
| 00000 = a | 01000 = i | 10000 = q | 11000 = y |
| 00001 = b | 01001 = j | 10001 = r | 11001 = z |
| 00010 = c | 01010 = k | 10010 = s | 11010 = ? |
| 00011 = d | 01011 = l | 10011 = t | 11011 = ? |
| 00100 = e | 01100 = m | 10100 = u | 11100 = ? |
| 00101 = f | 01101 = n | 10101 = v | 11101 = ? |
| 00110 = g | 01110 = o | 10110 = w | 11110 = ? |
| 00111 = h | 01111 = p | 10111 = x | 11111 = ? |
С помощью данной системы кодирования слово «hello» будет представлено в компьютере следующим образом «00111|00100|01011|01011|01110».
Этого достаточно для кодирования 26 букв стандартного латинского алфавита (6 символов остаются в запасе), но недостаточно для кодирования этого алфавита в виде строчных и прописных букв.
Общепринятым мировым стандартом кодирования символов долгое время служил формат ASCII (American Standard Code for Information Interchange). В нем каждый символ представлен 7 битами, то есть в целом этот формат обеспечивает возможность кодирования 128 (27 = 2 * 2 * 2 * 2 * 2 * 2 * 2) различных символов. Этого достаточно для кодирования всех строчных и прописных букв стандартного латинского алфавита, цифр от 0 до 9 и знаков препинания. Тем не менее, такой формат непригоден для кодирования диактрических знаков и других алфавитов, например, русского. Со временем появилось множество форматов, позволяющих кодировать символы различных языков. К сожалению, эти форматы часто несовместимы друг с другом.
В последнее время наибольшее распространение получил формат Unicode. Это единый формат, предназначенный для кодирования алфавитов всех языков, существующих на нашей планете. В формате Unicode каждый символ может быть представлен 32 битами, что позволяет кодировать миллионы различных символов, принадлежащих практически всем известным человечеству алфавитам – будь то японский, грузинский, древнеегипетский, готский или марийский. Формат Unicode поддерживается всеми современными операционными системами и интернет-браузерами. Таким образом, как видите, компьютер сам по себе в состоянии справиться с марийским алфавитом.
Проблемы с кодированием марийских символов возникают в том случае, когда файл сохранен не в формате Unicode. Во многих программах (например, Microsoft Word) файл автоматически сохраняется в формате Unicode. В некоторых программах сохранить файлы в формате Unicode невозможно, что, естественно, приводит к трудностям при работе с марийскими символами (с растущей тенденцией использования Unicode во всех программах можно надеется, что в ближайшем будущем этой проблемы не будет). Есть также программы, в которых формат Unicode хотя и не установлен по умолчанию, но может быть выбран пользователем при сохрании файла.
Например, при сохранении текстовых или html файлов в программе Microsoft Editor пользователю предоставляется возможность выбрать необходимый формат. Часто предлагаются различные варинты Unicode, из которых мы рекомендуем UTF-8 (Unicode Transformation Format).
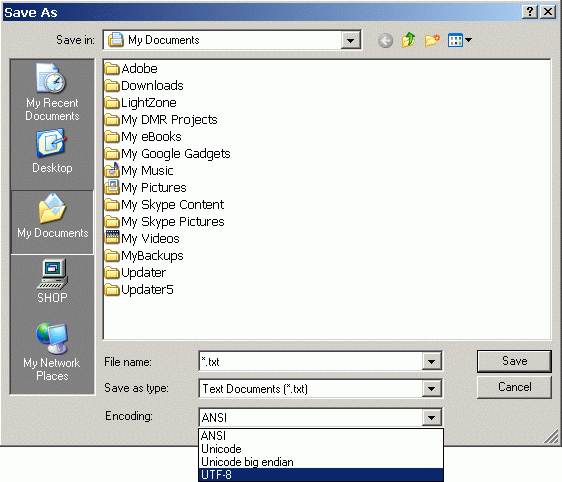
Выше представлен скриншот для Windows XP. Внешний вид скриншота может варьироваться в разных операционных системах, но основной принцип остается. Если вы сохранили файл в формате UTF-8, у вас не должно возникнуть проблем с марийскими символами.
Системы кодирования символов являются формой представления информции внутри компьютера. Сам же компьютер не «знает», как выглядят, например, буквы «a», «b», «c» и т. д. Чтобы придать информации, хрянящейся в компьютере в форме бит, графический облик, необходими шрифты. С помощью шрифтов задается тот или иной внешний вид символов.
Ни один из существующих шрифтов не поддерживает полный набор символов формата Unicode. Некоторые шрифты поддерживают исключительно стандартный латинский алфавит (и поэтому непригодны, например, для немецкого языка), некоторые поддерживают латинский алфавит с диактрическими символами, но не поддерживают кириллицу (что делает их пригодными для немецкого, но непригодными для русского языка). К сожалению, даже при использовании формата Unicode лишь очень немногие шрифты поддерживают расширенный набор кириллицы с марийскими символами, что, естественно, приводит к многочисленным затруднениям. Последствия нераспознавания определенного символа в определенном типе шрифта варьируются в зависимости от шрифта и используемой программы. Так, вместо нужного символа может появиться пустое место или пустая клетка (см. ниже). При отображении нужного символа также может использоваться другой шрифт (в котором поддерживается данный набор символов), в результате чего нарушается однообразие написания текста (см. ниже).
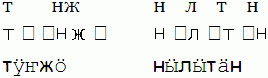
Во избежание этих проблем мы рекомендуем использовать пока ограниченный (но постоянно увеличивающийся) набор шрифтов, поддерживающих марийский алфавит. Вот некоторые из них:

Если вы собираетесь использовать один из этих шрифтов, но не можете найти его на вашем компьютере, вернитесь к списку необходимых действий выше и нажмите на соотвествующую ссылку, которая поможет вам найти и установить желаемый шрифт.
Обратите внимание, что при обмене документами Word и вэб-страницами с другими пользователями на компьютере получателя должны быть установлены те же шрифты, которые были использованы создателем документа. Только в этом случае удастся избежать проблем при отображении марийских символов. Для создания таких документов мы рекомендуем шрифт Microsoft Sans Serif, который поддерживает марийский алфавит и, как правило, входит в стандартный пакет всех современных операционных систем.
Естественно, во многих ситуациях не хочется ограничиваться одним шрифтом. Использование более редких шрифтов, таких как, например, DejaVu, не представляет сложностей в так называемых «статичных» документах. Если вы хотите, чтобы ваш документ при просмотре на других компьютерах выглядел точно так же, как на вашем, вы можете:
Для удобства набора текста на определенном языке неплохо иметь клавиатуру, содержащую все необходимые символы. Обратите внимание, что раскладка клавиатуры никак не связана с кодированием символов и шрифтами. Иными словами, отсутствие необходимых символов на клавиатуре еще не значит, что компьютер не способен распознавать и отображать эти символы. Представьте себе, что вы работаете с документом на немецком языке, сидя за американским компьютером. В этом случае, немецкие буквы «ä», «ö», «ü» и «ß» будут без проблем отображаться на экране, но возможность прямого ввода этих символов с клавиатуры будет ограничена.
Ни в одной из основных операционных систем не предусмотрена раскладка клавиатуры, необходимая для марийского языка. Ее нужно специально устанавливать либо в дополнение к основной раскладке (в этом случае пользователь может переключаться между двумя раскладками), либо взамен основной клавиатуры. На нашем сайте вы найдете установочные файлы для Windows (XP, Vista, 7) и MacOS X.
Сами марийцы, как правило, пользуются русской клавиатурой, которая содержит почти все (за исключением немногих) марийские символы. Выполнив необходимые действия, описанные здесь (для Windows XP, Windows Vista, Windows 7 и MacOS X), вы сможете вводить недостающие марийские буквы путем одновременного нажатия клавиши Alt – справа от знака пробел – и букв «а», «о», «у», «н», «ы» на русской клавиатуре.

Обратите внимание, что эти изменения никак не отразятся на использовании клавиатуры для набора текста на русском языке, так как они задействованы лишь при работе с марийским языком.
Предлагаемые нами раскладки клавиатуры содержат также некоторые нестандартные символы кириллицы, не принадлежащие марийскому алфавиту: «ӝ», «ӟ», «ӥ», «ӵ», являющиеся буквами удмурсткого языка. Такую раскладку можно использовать для всех основных финно-угорских языков Российской Федерации – марийского, коми, мордовского и удмуртского.
Для пользователей, никогда не работавших с русской клавиатурой, существуют специальные раскладки. Их отличие от обычной русской клавиатуры в том, что они максимально приближены к раскладке QWERTY, т.е. буквы кириллицы расположены на клавишах соответствующих им (если это соответствие имеется) латинских букв. Средний ряд раскладки, таким образом, представляет собой последовательность «асдфгхйклӧ», соответствующую «asdfghjkl(ö)» на латинице. Буквы кириллицы, не имеющие соответствий в латинице, располагаются либо на клавишах букв латиницы, которых нет в кириллице (например, «я» в левом верхнем углу на месте латинской «q»), либо по краям клавиатуры. Пользователям немецкой клавиатуры, например, предлагается следующая раскладка:

При одновременном нажатии клавиши Shift раскладка приобретает вид:

При одновременном нажатии клавиши Alt Gr раскладка выглядит следующим образом:

При одновременном нажатии двух клавиш Alt Gr и Shift:
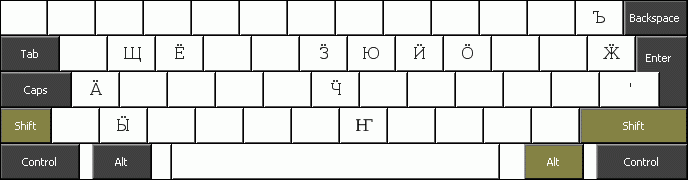
На нашем сайте вы найдете несколько очень похожих вариантов раскладки. Это связано с тем, что даже если расположение букв на многих клавиатурах одинаково, как, например, на немецкой и финской, они все же различаются расположением знаков препинания.
На данный момент мы предлагаем раскладки для следующих языков:
По желанию мы можем разработать раскладки и на основе других языков. Если вам нужна раскладка на основе, например, итальянской клавиатуры, обратитесь к нам.
 |
 |
 |
 |
||
| Работа над проектом The Mari Web Project главным образом проходит на отделении финно-угорских исследований Венского университета. Создание марийско-английского словаря было поддержано Австрийским научным фондом (FWF: P22786-G20). Вторая стадия нашего проекта The Mari Web Project: Phase 2 возможна благодаря финансовой поддержке Фонда Коне. Часть работы над проектом проводится в Институте финно-угорских и уральских исследований Мюнхенского университета Людвига-Максимилиана. | ||
| Последнее обновление:10 июля 2014 года | ||